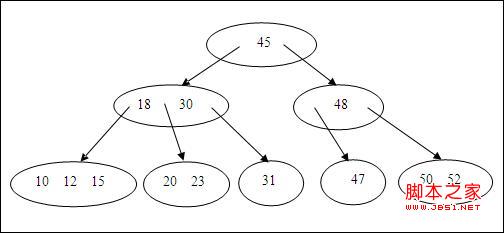
B树是为磁盘或其他直接存储设备设计的一种平衡查找树。如下图所示。每一个结点箭头指向的我们称为入度,指出去的称为出度。树结构的结点入度都是1,不然就变成图了,所以我们一般说树的度就是指树结点的出度,也就是一个结点的子结点个数。有了度的概念我们就简单定义一下B树(假设一棵树的最小度数为M):
1.每个结点至少有M-1个关键码,至多有2M-1个关键码;
2.除根结点和叶子结点外,每个结点至少有M个子结点,至多有2M个子结点;
3.根结点至少有2个子结点,唯一例外是只有根结点的情况,此时没有子结点;
4.所有叶子结点在同一层。
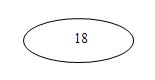
我们看看它的结点的结构,如下图所示:

每个结点存放着关键字和指向子结点的指针,很容易看出指针比关键码多一个。
由B树的定义我们可以看出它的一些特点:
1.树高平衡,所有叶结点在同一层;
2.关键字没有重复,按升序排序,父结点的关键码是子结点的分界;
3.B树把值接近的相关记录放在同一磁盘页中,从而利用了访问局部性原理;
4.B树保证一定比例的结点是满的,能改进空间利用率。
B树结点的大小怎么确定呢?为了最小化磁盘操作,通常把结点大小设为一个磁盘页的大小。一般树的高度不会超过3层,也就是说,查找一个关键码只需要3次磁盘操作就可以了。
在实现的时候,我是参照了《算法导论》的内容,先假定:
1.B树的根结点始终在主存中,不需要读磁盘操作;但是,根结点改变后要进行一次写磁盘操作;
2.任何结点被当做参数传递的时候,要做一次读磁盘。
在实现的时候其实还做了简化,每个结点除了包含关键码和指针外,还应该有该关键码所对应记录所在文件的信息的,比如文件偏移量,要不然怎么找到这条记录呢。在实现的时候这个附加数据就没有放在结点里面了,下面是定义树的结构,文件名为btrees.h,内容如下:
复制代码 代码如下:
/* btrees.h */
# define M 2
/* B树的最小度数M>=2
* 每个非根结点必须至少有M-1个关键字。每个非根结点至少有M个子女
* 每个结点可包含至多2M-1个关键字。所以一个内结点至多可以有2M个子女
*/
typedef int bool ;
struct btnode{ /* B树结点 */
int keyNum; /* 节点中键的数目 */
int k[2*M-1]; /* 键 */
struct btnode * p[2*M]; /* 指向子树的指针 */
bool isleaf;
};
struct searchResult{
struct btnode *ptr; /* 数据所在节点指针 */
int pos; /* 数据在节点中位置 */
};
下面是创建一颗空树的代码,文件名为btree.c:
复制代码 代码如下:
# include <stdio.h>
# include <stdlib.h>
# include "btrees.h"
/* 给一个结点分配空间 */
struct btnode * allocateNode( struct btnode *ptr){
int i,max;
ptr = ( struct btnode *) malloc ( sizeof ( struct btnode));
if (!ptr){
printf ( "allocated error!/n" );
exit (1);
}
max = 2*M;
for (i=0; i<max; i++)
ptr->p[i] = NULL; /* 初始化指针 */
memset (ptr->k, 0, (max-1)* sizeof ( int )); /* 初始化键的值*/
return ptr;
}
/* 创建一个空的B树,就一个根结点 */
struct btnode * btreeCreate( struct btnode *root){
root = allocateNode(root);
root->keyNum = 0;
root->isleaf = 1;
return root;
}
B树的插入都是在叶子结点进行的,由于B树的结点中关键码的个数是有限制的,最小度数为M的B树的结点个数是从M-1到2M-1个。比如下图是最小度数为2的B树(又称为2-3树),如下图所示,它的结点的个数就是1-3个。
先定位到要插入的位置,如果叶子结点的关键码个数还没达到上限,比如插入32,就比较简单,直接插入就行;如果叶子结点的关键码数到达了上限,就要分裂成2个子结点,把中间的关键码往上放到父节点中。但有极端的情况,就是父结点也是满的,就需要再次分裂,可能最后要把根结点也分裂了。但是这种算法不太好实现。
在《算法导论》中实现用的是另外一种思想,就是先分裂,在查找插入位置的过程中,如果发现有满的结点,就先把它分裂了,这就保证了在最后叶结点上插入数据的时候,这个叶结点的父结点总是不满的。下面我们看一个例子:
我们用逐个结点插入的方法创建一棵B树,结点顺序分别是{18, 31, 12, 10, 15, 48, 45, 47, 50, 52, 23, 30, 20},我们看看具体过程:
1.创建一个空的B树;
2.插入18,这时候是非满的,如下所示:
3.同理插入31和12,都比较简单,如下所示:

4.插入10,这时候根结点是满的,就要分裂,由于根结点比较特殊,没有父结点,就要单独处理,先生成一个空结点做为新的根结点,再进行分裂,如下所示:
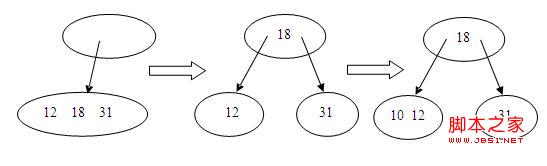
5.再插入15,48,45,由于非满,直接插入,如下所示:
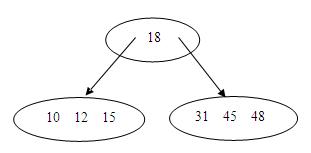
6.插入47,这次叶结点满了,就要先分裂,再插入,如下所示:
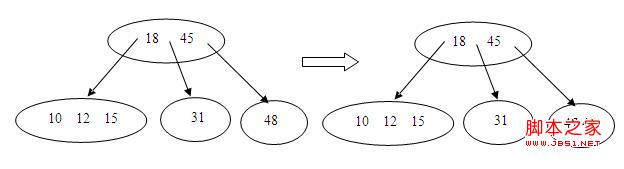
其他都是同样的道理,就不赘述了,下面是源码,加入到btree.c中,最后写了个main函数和一个广度优先显示树的方法,大家可以自己对比结果,代码的实现参照了《算法导论》和博客
http://hi.baidu.com/kurt023/blog/item/4c368d8b51c59ed3fc1f10cc.html
他博客里面已经实现了,只是在定义B树的时候指针数和关键码数成一样了,我于是自己重写了一下。
复制代码 代码如下:
//函数目的:分裂存储数达到最大的节点
void btreeSplitChild( struct btnode *parent, int pos, struct btnode *child){
struct btnode *child2;
int i;
//为新分裂出的节点分配空间
child2 = allocateNode(child2);
//与被分裂点同级
child2->isleaf = child->isleaf;
//设置节点数
child2->keyNum = M-1;
//复制数据
for (i=0; i<M-1; i++)
child2->k[i] = child->k[i+M];
//如果不是叶节点,复制指针
if (!child->isleaf)
for (i=0; i<M; i++)
child2->p[i] = child->p[i+M];
child->keyNum = M-1;
//将中间数作为索引插入到双亲节点中
//插入点后面的关键字和指针都往后移动一个位置
for (i=parent->keyNum; i>pos; i--){
parent->k[i] = parent->k[i-1];
parent->p[i+1] = parent->p[i];
}
parent->k[pos] = child->k[M-1];
parent->keyNum++;
parent->p[pos+1] = child2;
}
/* 函数目的:向非满的节点中插入一个数据
* 注意:插入前保证key在原来的B树中不存在
*/
void btreeInsertNoneFull( struct btnode *ptr, int data){
int i;
struct btnode *child; //要插入结点的子结点
i = ptr->keyNum;
//如果是叶节点,直接插入数据
if (ptr->isleaf){
while ((i>0) && (data<ptr->k[i-1])){
ptr->k[i] = ptr->k[i-1];
i--;
}
//插入数据
ptr->k[i] = data;
ptr->keyNum++;
}
else { //不是叶节点,找到数据应插入的子节点并插入
while ((i>0) && (data<ptr->k[i-1]))
i--;
child = ptr->p[i];
if (child->keyNum == 2*M-1){
btreeSplitChild(ptr, i, child);
if (data > ptr->k[i])
i++;
}
child = ptr->p[i];
btreeInsertNoneFull(child, data); //在子树中递归
}
}
/* 插入一个结点 */
struct btnode * btreeInsert( struct btnode *root, int data){
struct btnode * new ;
/* 检查是否根节点已满,如果已满,分裂并生成新的根节点 */
if (root->keyNum == 2*M-1){
new = allocateNode( new );
new ->isleaf = 0;
new ->keyNum = 0;
new ->p[0] = root;
btreeSplitChild( new , 0, root);
btreeInsertNoneFull( new , data);
return new ;
}
else { //还没到最大数据数,直接插入
btreeInsertNoneFull(root, data);
return root;
}
}
//函数目的:广度优先显示树
void btreeDisplay( struct btnode *root){
int i, queueNum=0;
int j;
struct btnode *queue[20];
struct btnode *current;
//加入队列
queue[queueNum] = root;
queueNum++;
while (queueNum>0){
//出队
current = queue[0];
queueNum--;
//移出第一个元素后后面的元素往前移动一个位置
for (i=0; i<queueNum; i++)
queue[i] = queue[i+1];
//显示节点
j = current->keyNum;
printf ( "[ " );
for (i=0; i<j; i++){
printf ( "%d " , current->k[i]);
}
printf ( "] " );
//子节点入队
if (current!=NULL && current->isleaf!=1){
for (i=0; i<=(current->keyNum); i++){
queue[queueNum] = current->p[i];
queueNum++;
}
}
}
printf ( "/n" );
}
int main()
{
struct btnode *root;
int a[13] = {18, 31, 12, 10, 15, 48, 45, 47, 50, 52, 23, 30, 20};
int i;
root = btreeCreate(root);
for (i=0; i<13; i++){
root = btreeInsert(root, a[i]);
btreeDisplay(root);
}
return 0;
}
运行结果:
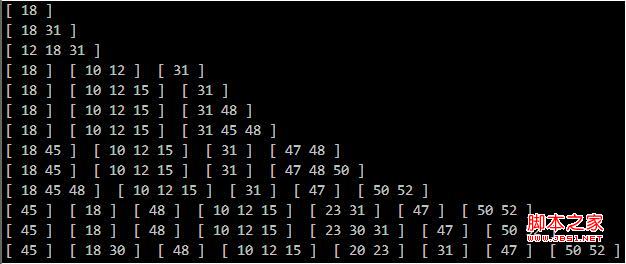
同样一批关键码用不同算法生成的B树可能是不同的,比如4个关键码的结点[1,2,3,4]分裂的时候,把2或3放上去都可以;同样的算法插入顺序不同也可能不同。
附件中是源码,在Linux下编译通过。
【c语言B树深入理解】相关文章: