“峰回路转疑无路,柳暗花明又一村”。当在频率上遇到瓶颈时,英特尔选择了用双核的方式来继续维持处理器性能上的增长,尽管仓促上阵的Pentium D备受争议,但是英特尔还是抢到了“双核”的先机;当然事后英特尔并没有闲着,这位半导体业的大佬其实很明白,如果拿不出更先进的性能增长方案,自己在市场上将更加被动。
冰冻三尺非一日之寒,凭借着在半导体领域多年的积累,英特尔在今年三月份的IDF上宣布在下一代处理器中将放弃现在的“NetBurst”架构而转向新的“Core”架构,如果说上次变革英特尔是被动接受的话,那么这次很显然是“未雨绸缪”。本文的主角也正是将在今年下半年登场的“Core”……
一、精简流水线长度,增加解码器单元
与NetBurst架构相比,Core架构最明显的变化就是处理器中流水线级数(长度)大大减少。长期以来,英特尔处理器一直备受“高频低能”的困挠—长流水线可以很容易达到更高的工作频率,但是性能增长却远没有跟频率成正比;而且,提高频率的同时还有一个非常头痛的副产品—功耗(TDP)。
此次英特尔在Core架构中大胆放弃了NetBurst架构的思路,只使用了14级流水线。这种改进使以后频率的提升变得相对困难了一些,但对实际性能来说却有莫大的帮助—流水线长度降低以后,低频率、低功耗和高性能可以兼得。
多年以前,AMD曾经在K5处理器上尝试过使用四组指令解码器,但是没有成功;以后很长的一段时间里,Intel和 AMD都沿用了三组指令解码器的设计。
英特尔在NetBurst架构中试图通过导入Trace Cache存放编码后的微指令,并替代高性能复数指令编码器,但是收效甚微。此次在Core架构中重新回归四组指令编码器的设计,更多的指令解码器理论上意味着更高的性能;但是要把这种优势变成实际的效果并不容易,不过从目前已经公布的测试结果来看英特尔做得不错。
二、对双核心的优化设计 英特尔现在的桌面级双核心处理器是Pentium D,但是这款产品及其衍生的服务器版本(Dempsey)都是仓促之作。具体表现为它们没有L2缓存的共享机制,两个核心之间的通讯甚至还需要通过前端总线(FSB)中转,这样会严重限制双核处理器之间的协作应用。
Yonah是英特尔第一个真正意义上从头开始的双核心处理器,两个核心可以共享L2缓存;但作为一款针对移动平台的产品,新特性带来的好处并没有完全体现出来*。
*注释:共享L2缓存的真正好处是能够大大减少缓存一致性监听所带来的性能下降—但是这种性能下降对于工作站和服务器平台来说是非常严重的问题,而对于桌面和移动平台来说就不那么明显了。
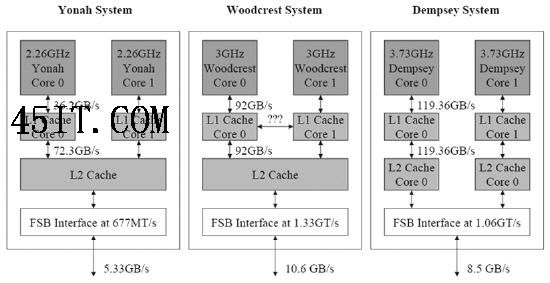
Yonah、Woodcrest(Core)与Dempsey处理器的结构对比。Core继承了Yonah的双核心设计方式—共享L2缓存和系统总线接口,同时增加了L1缓存之间的通讯;不过Core的内部带宽更接近Dempsey,片上缓存的带宽远远超过Yonah,同时系统总线的带宽也有大幅提升 Core架构延续了Yonah的这一特性,因此服务器版本(Woodcrest)将比前代产品(Dempsey)提供更好的性能。此外,英特尔方面多次提到Core架构还可能实现在L1缓存之间直接传输数据,不过到目前为止英特尔对此并没有透露更多的细节,但我们可以相信如果这是真的话,Core的性能无疑会再提升一个档次。
三、指令融合和分支预测体系 此次英特尔从NetBurst架构到Core架构的转型,还有一项非常明显的改进。那就是x86指令的融合,它可以说是Core架构独有的特性之一(图3)。
在处理器内部,x86指令被称为Macro-ops,而内部指令被称为uops,而Macro-ops融合可以将两个Macro-ops融合成一个uops。举个例子来说,我们可以把x86 Compare(比较)指令与x86 Jump(跳转)指令融合在一起,生成一条单独的uops(比较并跳转指令)。在Core中每个解码器都可以完成这样的优化工作,但是每周期内最多只能有一个解码器完成这样的融合,所以最大指令解码带宽是每周期4 1个x86指令。
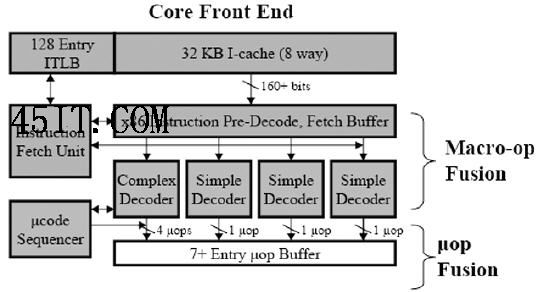
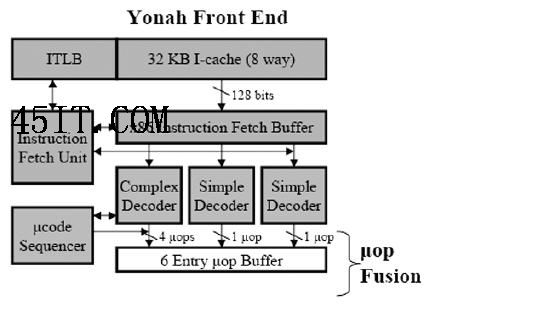
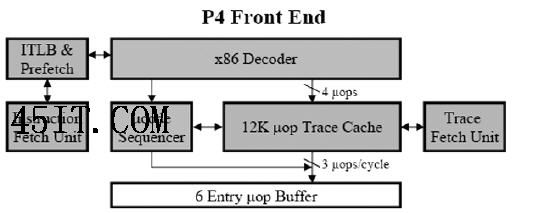
对比英特尔不同架构中的提取指令/译码单元,可以看到Core要比Yonah和Pentium 4更加复杂 这种融合的好处是显而易见的:首先,融合之后需要执行的指令变少了,这等于直接提高了处理器的执行性能;其次,乱序执行可以因此变得更有效率,因为融合的过程实际上就是让指令窗口检查更多的程序代码,更大限度地发现指令之间的并行性,从而提高处理器的执行效率。不过颇具讽刺意味的是,从某种程度上来看这种x86指令的融合机制使得x86处理器更加RISC(简单指令集)化而不是CISC(复杂指令集)化。
为了降低长流水线带来的负面影响,英特尔曾经在NetBurst架构的分支预测上花费了相当大的精力,其分支预测的错误率号称比上一代架构下降了33%以上,而Core架构的分支预测能力在NetBurst的基础上又有进步。
在新架构中,英特尔不仅保留了上一代架构的跳转目标缓冲区、跳转地址计算器以及返回地址堆栈,而且还采用两种新的预测算法—“循环探测”能够正确探测(程序的)循环退出,而“间接分支预测”可以基于全局的历史信息获取(预测)正确的目标地址。除此之外,Core架构还引入了其它的一些新特性,例如在原先的架构中,跳转命令总会引入一个周期的流水线空置,但是在Core架构中引入了一个用于存储跳转发生位置的队列,大部分的流水线空置都将被消除。诸多新特性的引入,使得Core的分支预测能力空前强大,从性能上来说无异于如虎添翼。
#p#
四、乱序引擎和执行单元 熟悉Yonah架构的朋友一眼就会发现Core的乱序引擎与前者有太多“神似”的地方,所以我们说Core的乱序引擎是Yonah的“翻版”也并不为过。它们确实有太多相似的结构,包括寄存器别名表,寄存器分配器以及重序缓冲(ROB)。
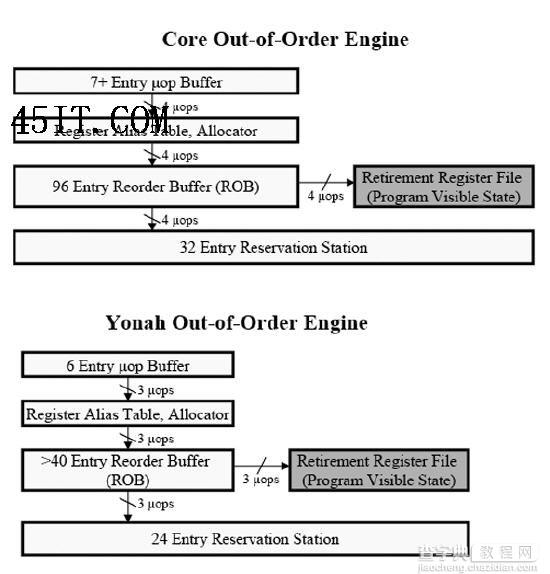
Core架构中的乱序引擎只是比Yonah增加了更多的执行单元,这样有利于同时处理更多的指令并更好地挖掘指令之间的并行度 Pentium 4(桌面级,下同)和Yonah架构的最大吞吐量都是每周期3 uops,而Core架构的设计为每周期4 uops。除此之外,Core的保留站(Reservation station)也比Yonah大得多(32vs.24 );不过这个值与Pentium 4直接对比有些困难,因为在Pentium 4中使用的是分布式调度器而不是保留站(Pentium 4共有46个调度项空间,8个用于内存操作指令,剩下38个用于ALU和FPU)。
Core架构在设计上比Pentium 4和Yonah多一个额外的分发端口,所以它可以每周期持续执行三条指令。更重要的是,Core有更平衡的执行单元分配机制—在Pentium 4处理器中,很多操作都集中在一号端口,这样很容易产生严重的冲突,而Core有效避免了这一点。
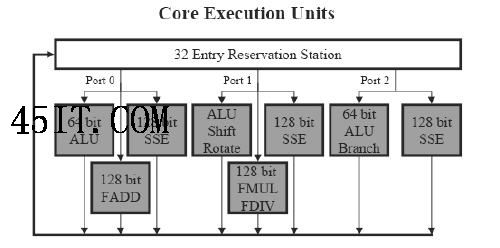
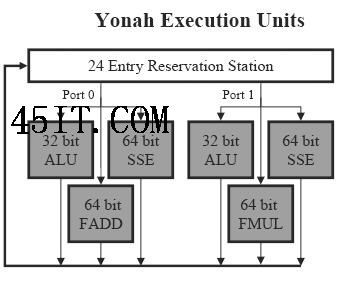
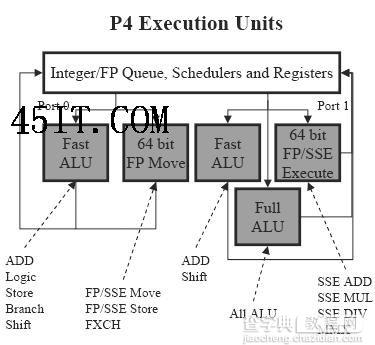
在Core架构中有三个端口用于执行单元,其中包括3个128bit SSE单元、2个浮点单元和3个64bit整数单元,其中一号端口上(Port 1)的整数单元还可以用于处理128bit移位和循环移位操作。所有端口都可以分发浮点Move指令,FPU和SSE单元在某种程度上可以实现部分硬件电路的共享。这种设计非常高效,Yonah和Pentium 4远不能与之相提并论 除了对整数计算能力的优化之外,Core架构同样也大幅提高了浮点和SSE计算的能力。在Core架构中三个SSE单元并不是完全对等的,但它们之间的差别非常小;而且SSE 单元采用完全流水线化的设计,每个单元都可以在单个周期内执行相应的128bit SSE指令。相比之下Pentium 4中的SSE单元相对不足,它的两个64bit SSE单元需要两个周期才能执行一条128bit SSE指令。
五、缓存和内存系统 基于Core架构的微处理器拥有更多的执行单元,这就要求缓存与内存子系统也要大幅提高性能以适应其它部分的变化。
Core和Yonah的缓存都是写回式(Write back)结构,使用64byte的缓存列大小;而Pentium 4的L1缓存是写通式(Write Through),缓存列大小64byte,L2缓存是写回式。在某种条件下*,Core架构还可以实现在两个核心L1缓存之间直接传输缓存数据。
*注释:英特尔方面只是表示可以在L1缓存之间实现通讯,但到目前为止并没有透露更详细的资料。
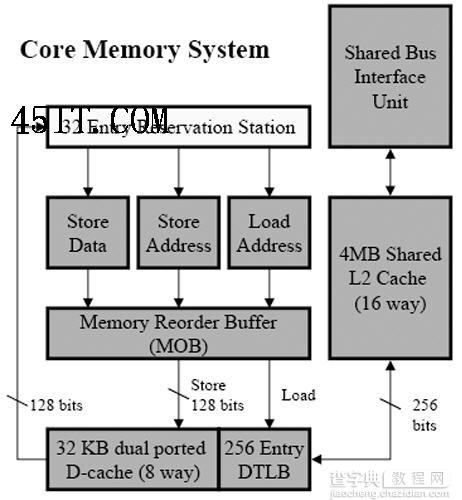
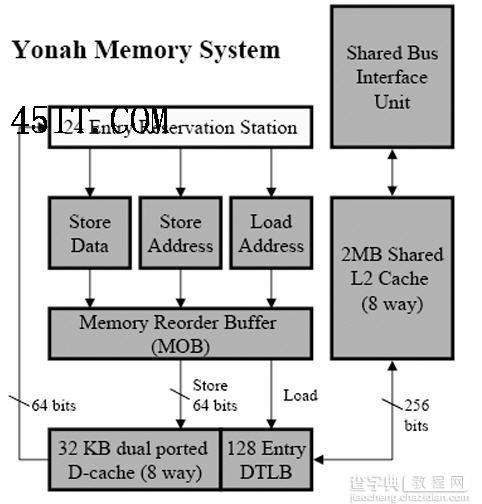
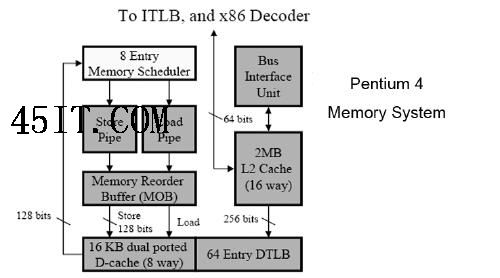
Core架构的缓存子系统结构与Yonah几乎完全相同,唯一的区别只是带宽大于后者 内存子系统也引入了新的预取策略来配合共享缓存的设计,以期达到最高的效率—L1缓存中引入了多个预取器,而L2缓存的预取器可以根据当前数据访问的模式和密度在两个处理器之间动态分配带宽资源;与此同时,前端总线接口(FSB)也采用类似的仲裁方式以确保两个核心之间的平衡。
六、Core架构的硬件改进 英特尔在Core架构中的改进只能用“大刀阔斧”来形容,除了上面我们介绍到的各个子系统的局部改进之外,还引入了很多先进的硬件技术来提高处理器的整体表现。
基于Prescott核心的Pentium 4/D处理器的高发热量可以说是用户的切肤之痛,在进入65nm制程之后,情况虽然有所改善但是处理器的发热问题依然十分头痛,这就对处理器的温控系统提出了更高的要求。在Core架构中,英特尔设计了一个片上数字热敏元件来替代原先的温控二级管。有消息称,如果这个小部件发现处理器的实际功耗离最大值(TDP)还有一段距离时,会动态提高处理器的运行频率;如果这种说法成立的话,这项技术很有可能会用到Conroe和Woodcrest中,而对功耗相对敏感的Merom不会采用这项技术。
Core架构中的绝大多数部件都可以实现深度“屏蔽”以获得更好的性能功耗比—它的两个核心可以实现完全独立的管理,许多单元也可以整个进入深度睡眠状态;而且绝大多数情况下,这种屏蔽不会降低性能,晶体管数量和发热量之间的矛盾得到了很好的解决。
Core处理器也包含了新的指令集—SSE4。SSE4指令集原先计划用在Tejas核心(Prescott的后继产品)中,不过随着Tejas计划的取消,Core架构接过了接力棒。但是因为历史的原因,新的SSE4指令集在Core架构中性能提高有限,远没有当初引进SSE2时那么明显,只能算是锦上添花。
七、规格和性能 Core微处理器家族中目前公布的最高频率为3.0GHz(未来预计会有3.33GHz的产品出现)。目前来自英特尔方面的资料声称Merom相对目前的移动处理器约有20%的性能提升,Conroe相对目前的桌面级产品大约会有40%的性能提升,而针对服务器市场的Woodcrest提升幅度最为明显—相对于目前的Dempsey会有80%左右的性能提升。
在性能提高的同时,处理器的发热也得到了很好的控制,其中Merom 35W、Conroe 65W以及Woodcrest 80W;而且英特尔会根据用户需求提供低功耗的版本,如针对刀片服务器市场的低电压版本Woodcrest将牺牲一些频率,将TDP控制在40W左右。
目前得到的这些资料都是相对值,并且在正式发布之前英特尔仍有可能对Core架构作进一步调整和优化。但是从目前已经公布的测试数据来看,新架构的表现非常优秀,各项性能指标都大幅度超过竞争对手的产品。
写在最后 从技术上看,“核心微架构”是近几年来英特尔公布的一个全新的x86架构;相对于以往的产品,英特尔在各方面都进行了大规模的改进,而且相信这个架构将会在一段时间内对整个处理器行业产生深远的影响。 从发布时间上看,英特尔将在今年第三季度初期首先发布面向服务器市场的Woodcrest,然后在第三季度晚些时候推出桌面级的Conroe,最后在第四季度或明年初推出面向移动市场的Merom。
近年来英特尔除了在移动处理器领域保持了绝对的领先地位之外,在桌面级和处理器市场上不断受到竞争对手的强有力挑战;而这次英特尔放出Core架构来重振旗鼓,无疑是想打一场彻彻底底的“翻身仗”,而且竞争对手到目前为止还没有拿出更有效的应对策略。《微型计算机》将一如既往地关注这方面的最新进展。
【变革进行时全面解析英特尔新架构】相关文章:
★ i7-4790K怎么样?Intel酷睿i7-4790K详细评测图文介绍
★ i7-6700K怎么样?Intel酷睿i7-6700K详细参数介绍