Linux环境:CentOs6.4
Hadoop版本:hadoop-0.20.2
内容:统计hadoopbin下的所有文件中单词出现的个数。
所用到的命令有:
//创建input文件夹
./hadoop fs -mkdir input
//将所有的需要统计单词个数的文件放在input文件夹下
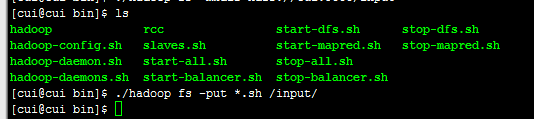
./hadoop fs -put *.sh /input/
//运行wordcount将结果输出到output文件夹下
./hadoop jar hadoop-examples-0.20.2.jar wordcount /input /output
//验证某个单词的个数
grep xxx *.sh
grep xxx *.sh|wc
第一步:确定HDFS、MapReduce、jobTracker等是否正常启动。查看http://www.jb51.net/softjc/137245.html
第二步:在Hadoop文件系统根目录中创建input文件夹。
执行命令:

打开网页查看input文件夹是否创建成功:
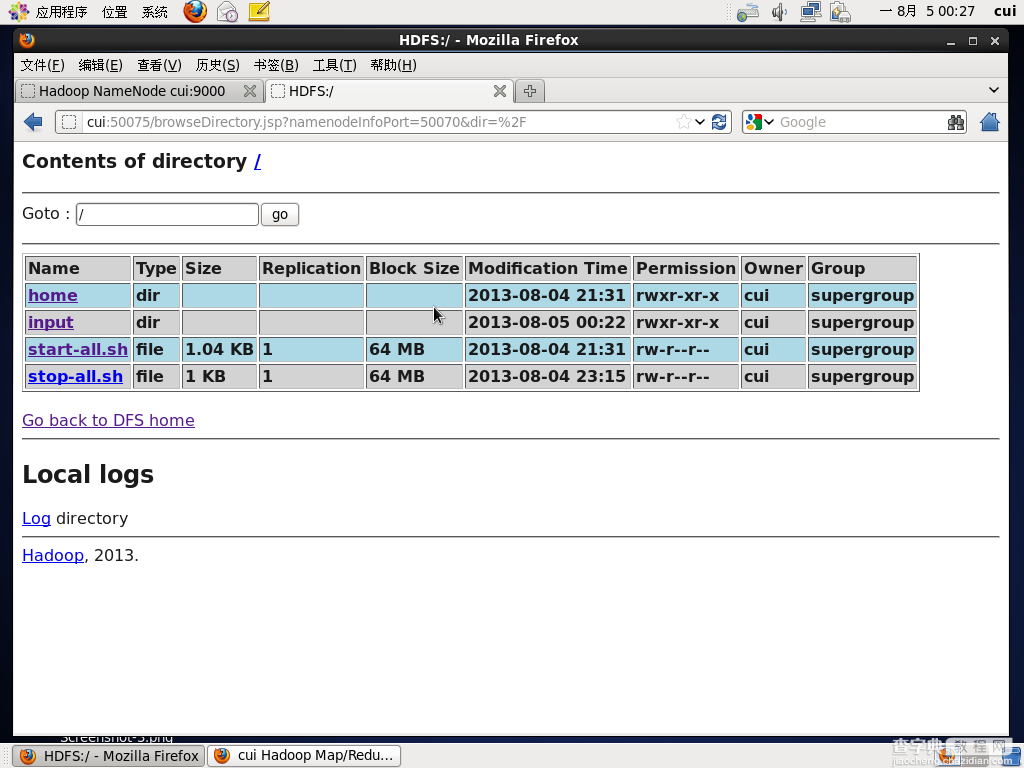
上图表明已经成功。
第三步:将bin目录下的所有文件放到hadoop文件系统的input目录下。
执行命令:
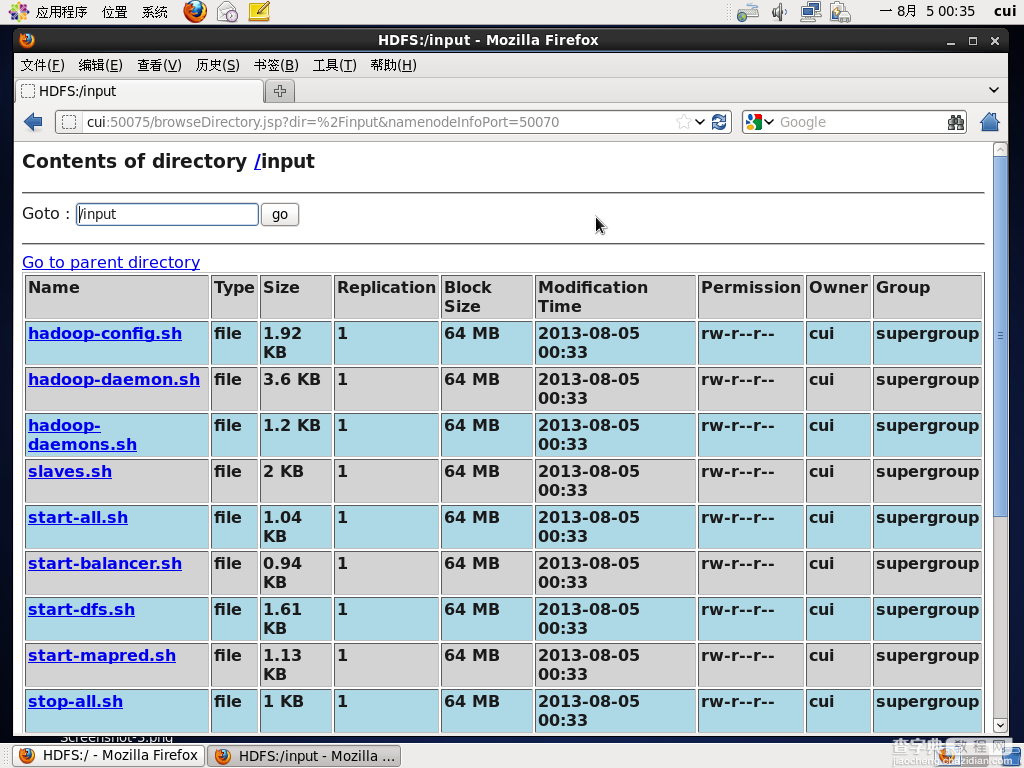
通过浏览器查看input文件夹下是否已经存在所存放的文件。
第四步:执行wordcount命令统计单词个数。
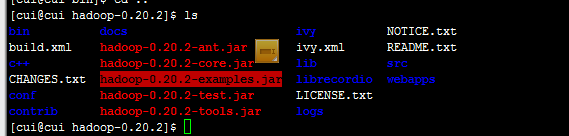
回到Hadoop文件夹下,找到统计个数的jar包。如图,在hadoop-0.20.2目录下有一个hadoop-0.20.2-examples.jar。
运行命令执行此jar,统计个数。并将输出结果放在output目录下。命令如下:
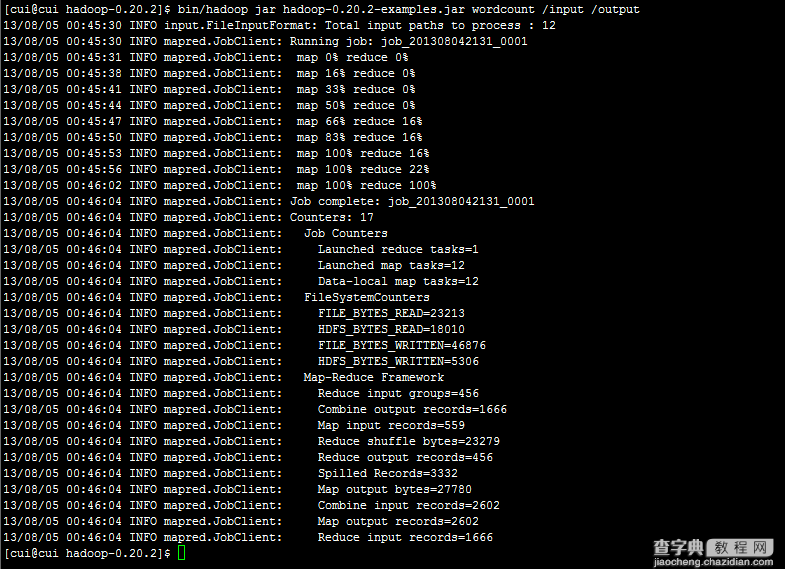
运行成功。
第五步:验证结果是否正确。通过命令统计某一单词的个数,与MapReduce统计的个数进行对比。
通过命令查看文件中language单词的个数为12个,如图。

查看MapReduce运行结果,如图:
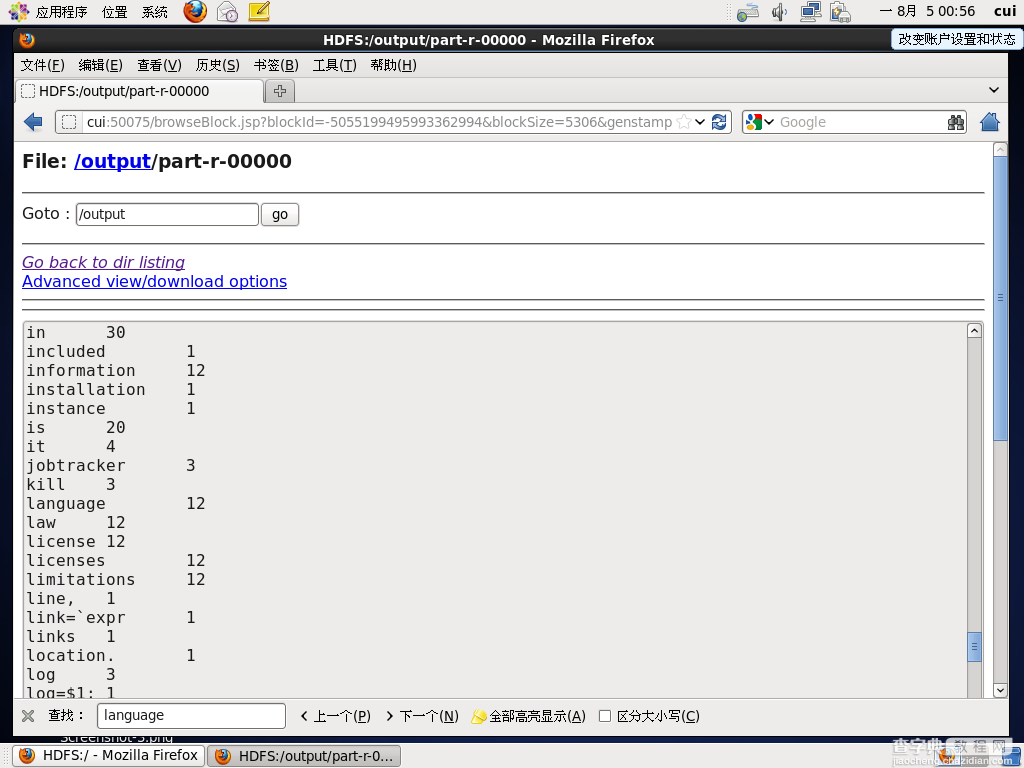
运行结果相同。
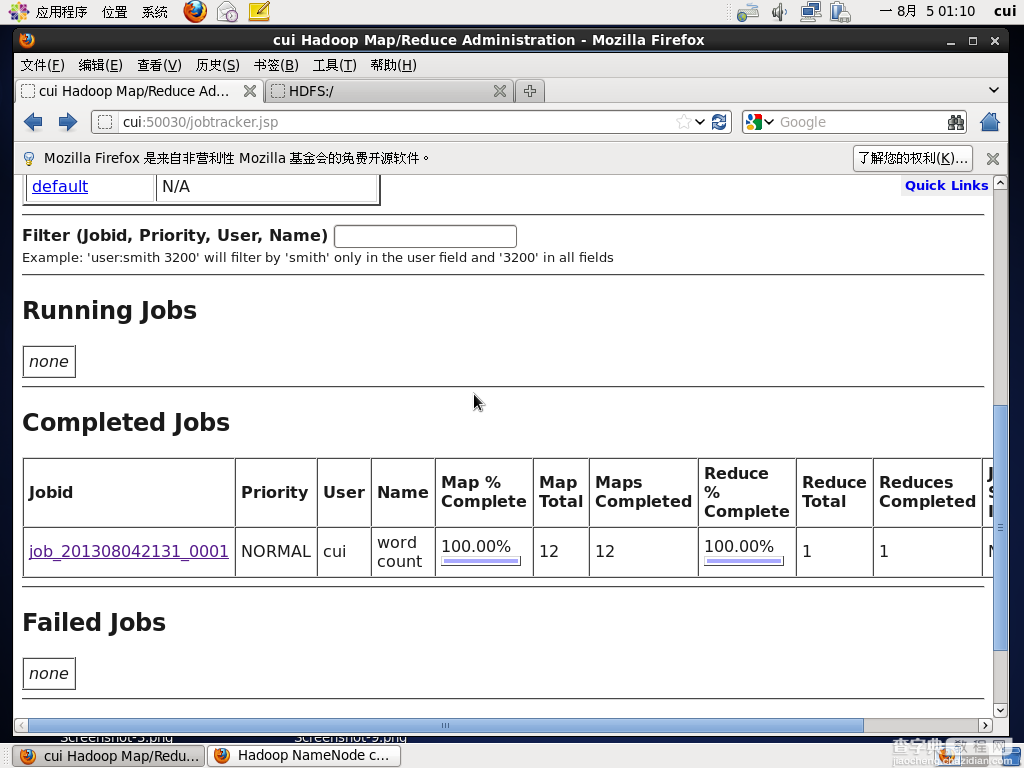
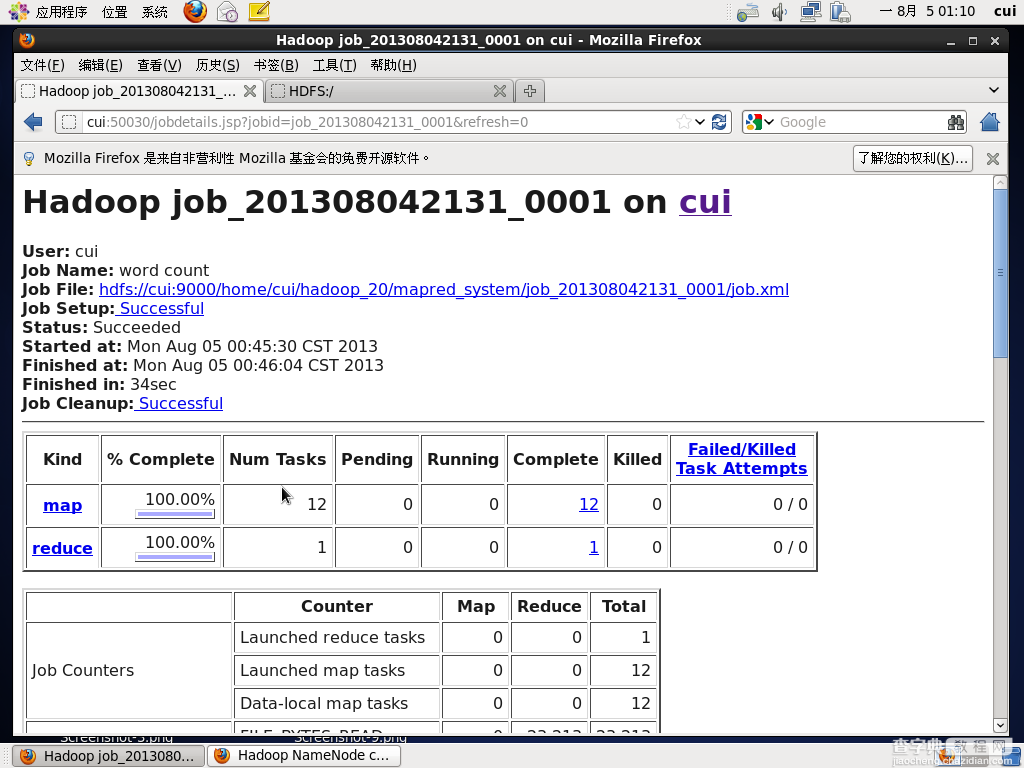
附:从过页面查看运行状态
【hadoop入门之统计单词在文件中出现的个数示例】相关文章:
★ android studio怎么添加.so文件?android studio加载so文件的方法
★ Android studio生成javadoc文件的教程
★ Android studio项目代码与剪切板做对比的两种方法