有时候我们看到一个网站的文章,想要把这些文章保存下来,一篇一篇的复制保存很麻烦,这个时候就需要用到火车头采集器把文章采集下来保存了。下面介绍一下如何用火车头采集器采集文章。
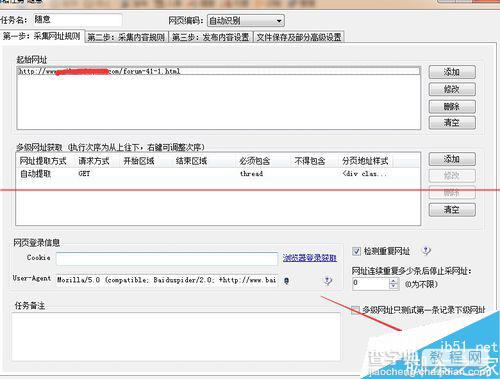
第一步采集网址,下载好火车头采集器后打开,新建一个任务,任务名随意。把需要采集的网站文章列表页网址添加到起始网址。从图中看出该列表页有34页,每页有N篇文章。
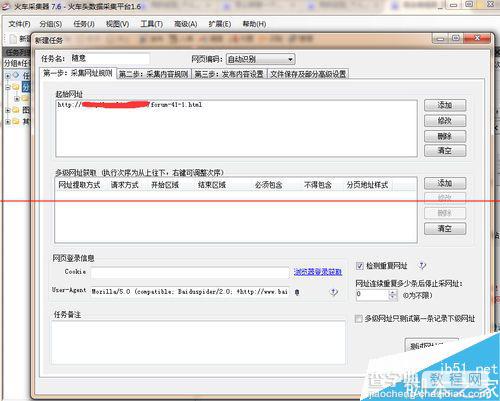
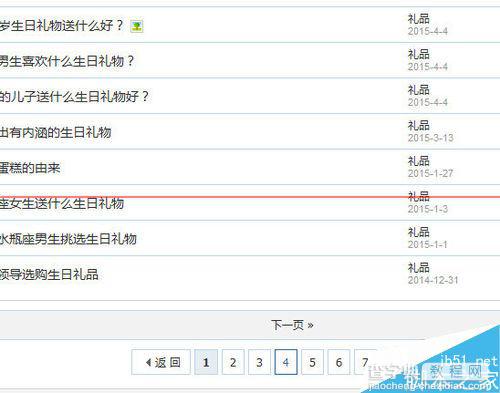
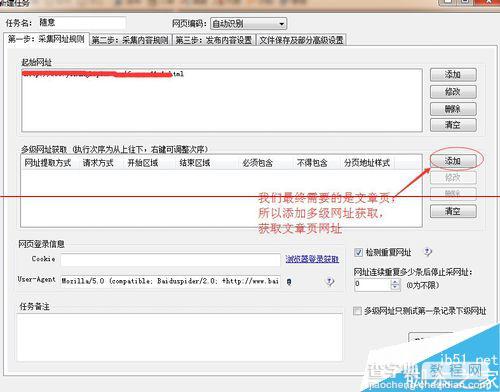
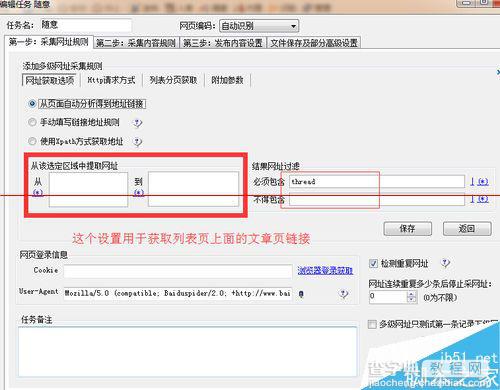
列表页会一级网址,添加多级网址获取,从而获取二级网址(文章页网址)
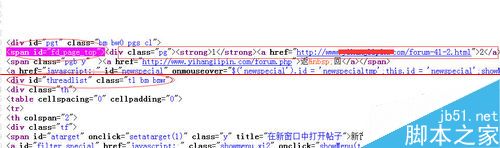
设置列表分页获取,3个地方分别是:分页源代码前面和后面还有中间位置。这一步用于获取列表页面链接,因为有34个列表页面。设置完保存。
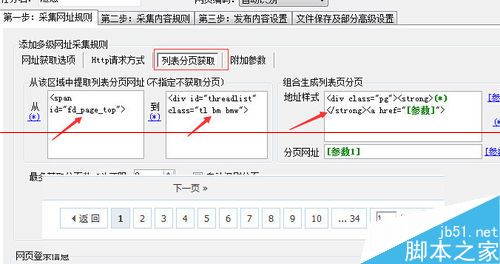
网址获取选项,这一步用于获取列表页上面文章页的链接,根据自己需要设置需要截取的部分和根据网址的结构设置包含与不包含某些字符。为空即没限制,设置完保存。
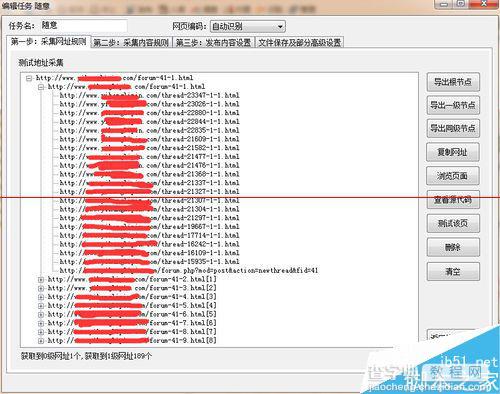
设置好链接采集规则后,可以测试网址,看测试结果调整规则。看图可以看到采集链接规则从起始链接到全面列表页再到列表页上的文章页链接都已经成功采集。
第二步是采集内容,首先修改标题规则,在页面源代码里面找到标题的代码,把标题前后代码负责过去截取出标题。保存。
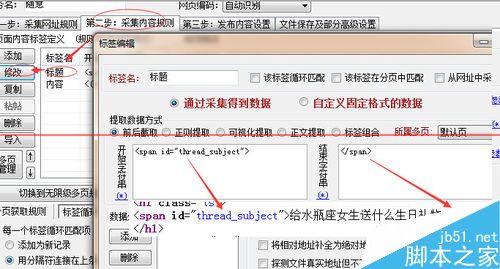
修改内容采集规则,跟标题规则差不多,也是源代码里面找到内容的前后代码。这里内容会有一些其他html标签,所以得添加一个html标签排除的规则。
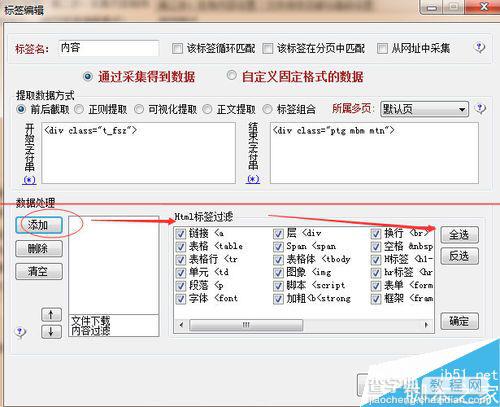
完成后,测试看一下结果,从测试结果来调试规则,直到测试结果是自己想要的内容为止。
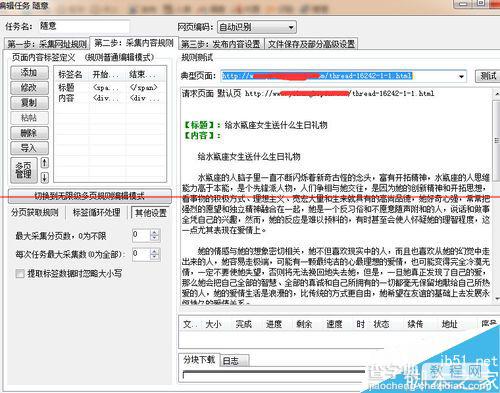
第三步是采集导出。前面1、2两步把规则设置好,最后就要把文章导出了。先做一个导出的模版。
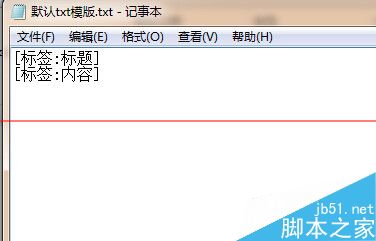
然后选择方式二,把每一篇文章都分别记录到一个txt文本,保存位置自己选择,模板选择刚刚做好的导出模版.保存的文件名用文章标题为命名。其他默认,保存。
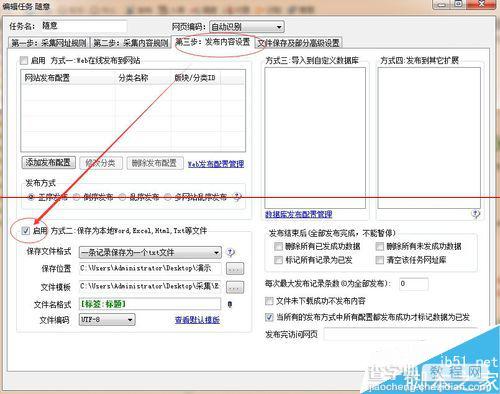
把采集网址,采集内容,发布3个选项框都勾选,然后开始采集。完成后文本就自动生成在刚刚保存的文件夹里面了。
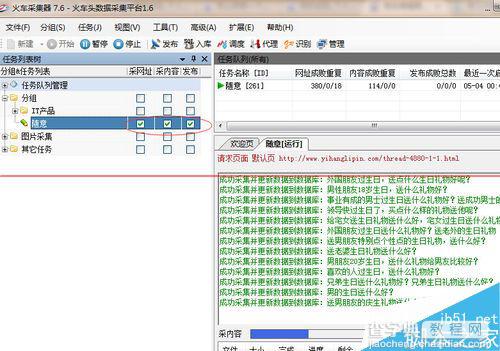
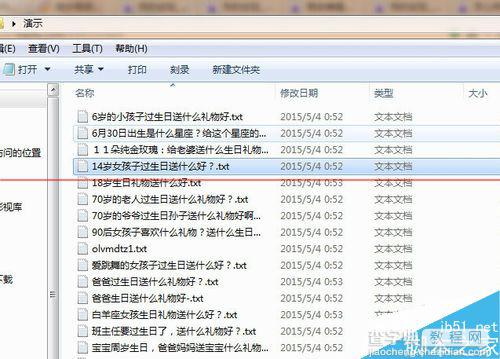
火车头采集器采集文章教程到此就完成了,由于每个网站都是不一样的,所以这里只能用一个网站演示,只是一个方法思路,自己采集文章还需要灵活变通。
【火车头采集器怎么采集文章?】相关文章: