怎么保存树状结构的数据呢?在 SQL 中常用的是双亲节点法。创建表如下
CREATE TABLE category ( id LONG, parentId LONG, name String(20) ) INSERT INTO category VALUES ( 1, NULL, 'Root' ) INSERT INTO category VALUES ( 2, 1, 'Branch1' ) INSERT INTO category VALUES ( 3, 1, 'Branch2' ) INSERT INTO category VALUES ( 4, 3, 'SubBranch1' ) INSERT INTO category VALUES ( 5, 2, 'SubBranch2' )
其中,parent id 表示父节点, name 是节点名称。
假设当前欲获取某一节点下所有子节点(获取后代 Descendants),该怎么做呢?如果使用程序(Java/PHP)递归调用,那么将在数据库与本地开发语言之间来回访问,效率之低可想而知。于是我们希望在数据库的层面就可以完成,——该怎么做呢?
递归法
经查询,最好的方法(个人觉得)是 SQL 递归 CTE 的方法。所谓 CTE 是 Common Table Expressison 公用表表达式的意思。网友评价说:“CTE 是一种十分优雅的存在。CTE 所带来最大的好处是代码可读性的提升,这是良好代码的必须品质之一。使用递归 CTE 可以更加轻松愉快的用优雅简洁的方式实现复杂的查询。”——其实我对 SQL 不太熟悉,大家谷歌下其意思即可。
怎么用 CTE 呢?我们用小巧数据库 SQLite,它就支持!别看他体积不大,却也能支持最新 SQL99 的 with 语句,例子如下。
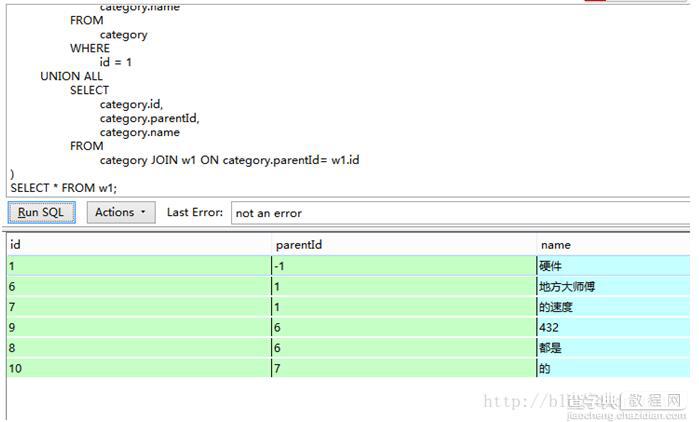
WITH w1( id, parentId, name) AS ( SELECT category.id, category.parentId, category.name FROM category WHERE id = 1 UNION ALL SELECT category.id, category.parentId, category.name FROM category JOIN w1 ON category.parentId= w1.id )
SELECT * FROM w1;其中 WHERE id = 1 是那个父节点之 id,你可以改为你的变量。简单说,递归 CTE 最少包含两个查询(也被称为成员)。第一个查询为定点成员,定点成员只是一个返回有效表的查询,用于递归的基础或定位点。第二个查询被称为递归成员,使该查询称为递归成员的是对 CTE 名称的递归引用是触发。在逻辑上可以将 CTE 名称的内部应用理解为前一个查询的结果集。递归查询没有显式的递归终止条件,只有当第二个递归查询返回空结果集或是超出了递归次数的最大限制时才停止递归。递归次数上限的方法是使用 MAXRECURION。
相应地给出查找所有父节点的方法(获取祖先 Ancestors,就是把 id 和 parentId 反过来)
WITH w1( id, parentId, name, level) AS ( SELECT id, parentId, name, 0 AS level FROM category WHERE id = 6 UNION ALL SELECT category.id, category.parentId, category.name , level + 1 FROM category JOIN w1 ON category.id= w1.parentId ) SELECT * FROM w1;
无奈的 MySQL
SQLite ok 了,而 MySQL 呢?
在另一边厢,大家都爱用的 MySQL 却无视 with 语句,官网博客上明确说明是压根不支持,十分不方便,明明可以很简单事情为什么不能用呢?——而且 MySQL 也好像没有计划在将来的新版本中添加 with 的 cte 功能。于是大家想出了很多办法。其实不就是一个递归程序么——应该不难——写函数或者存储过程总该行吧?没错,的确如此,——写递归不是问题,问题是用 SQL 写就是个问题——还是那句话,“隔行如隔山”,虽然有点夸张的说法,但我想既懂数据库又懂各种数据库方言写法(存储过程)的人应该不是很多吧~,——不细究了,反正就是代码帖来贴去呗~
我这里就不贴 SQL 了,可以看这里的,《MySQL中进行树状所有子节点的查询》
至此,我们的目的可以说已经达到了,而且还不错,因为这是不限层数的(以前 CMS 常说的“无限级”分类)。——其实,一般情况下,层数超过三层就很多,很复杂了,一般用户如无特殊需求,也用不上这么多层。于是,在给定层数的约束下,可以写标准的 SQL 来完成该任务——尽管有点写死的感觉~~
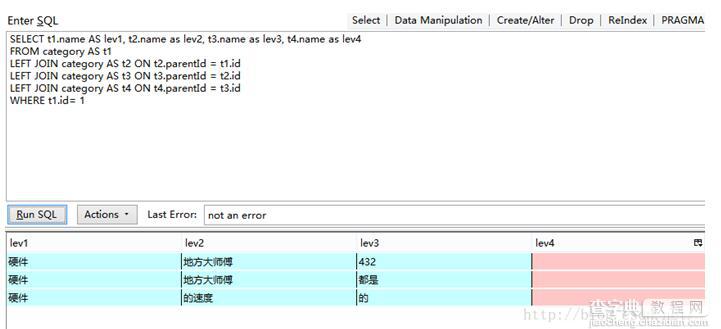
SELECT t1.name AS lev1, t2.name as lev2, t3.name as lev3, t4.name as lev4 FROM category AS t1 LEFT JOIN category AS t2 ON t2.parentId = t1.id LEFT JOIN category AS t3 ON t3.parentId = t2.id LEFT JOIN category AS t4 ON t4.parentId = t3.id WHERE t1.id= 1
相应地给出查找所有父节点的方法(获取祖先 Ancestors,就是把 id 和 parentId 反过来)
SELECT t1.name AS lev1, t2.name as lev2, t3.name as lev3, t4.name as lev4
FROM category AS t1
LEFT JOIN category AS t2 ON t2.id= t1.parentId
LEFT JOIN category AS t3 ON t3.id= t2.parentId
LEFT JOIN category AS t4 ON t4.id= t3.parentId
WHERE t1.id= 10优化版本
但是生成的结果和第一个例子相比起来有点奇怪,而且不好给 Java 用,——那就再找找其他例子
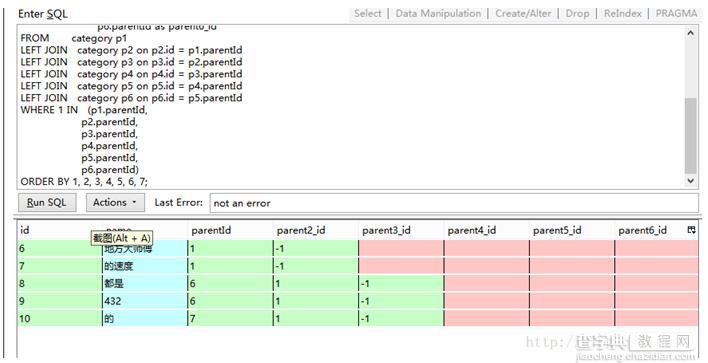
SELECT
p1.id,
p1.name,
p1.parentId as parentId,
p2.parentId as parent2_id,
p3.parentId as parent3_id,
p4.parentId as parent4_id,
p5.parentId as parent5_id,
p6.parentId as parent6_id
FROMcategory p1
LEFT JOIN category p2 on p2.id = p1.parentId
LEFT JOIN category p3 on p3.id = p2.parentId
LEFT JOIN category p4 on p4.id = p3.parentId
LEFT JOIN category p5 on p5.id = p4.parentId
LEFT JOIN category p6 on p6.id = p5.parentId
WHERE 1 IN (p1.parentId,
p2.parentId,
p3.parentId,
p4.parentId,
p5.parentId,
p6.parentId)
ORDER BY 1, 2, 3, 4, 5, 6, 7; 这个总算像点样子了,结果是这样子的。
相应地给出查找所有父节点的方法(获取祖先 Ancestors,就是把 id 和 parentId 反过来, 还有改改 IN 里面的字段名)
SELECT p1.id, p1.name, p1.parentId as parentId, p2.parentId as parent2_id, p3.parentId as parent3_id FROM category p1 LEFT JOIN category p2 on p2.parentId = p1.id LEFT JOIN category p3 on p3.parentId = p2.id WHERE 9 IN (p1.id, p2.id, p3.id) ORDER BY 1, 2, 3;
这样就很通用啦~无论你 SQLite 还是 MySQL。
其他查询:
查询直接子节点的总数:
SELECT c.* , (SELECT COUNT(*) FROM category c2 WHERE c2.parentId = c.id) AS direct_children FROM category c
•使用 with 语句递归,通俗易懂的例子(英文),我第一个成功的例子就是从这里 copy 的,另外还可以查层数 level 和反向的父节点:https://www.valentina-db.com/dokuwiki/doku.php?id=valentina:articles:recursive_query
•标准写法的出处(英文):http://stackoverflow.com/questions/20215744/how-to-create-a-mysql-hierarchical-recursive-query
•很好的总结贴(英文):http://mikehillyer.com/articles/managing-hierarchical-data-in-mysql/
•SQlite with 语句用法中文翻译(太晦涩,不懂鸟) http://blog.csdn.net/aflyeaglenku/article/details/50978986
•利用闭包做的树结构(书上说这个方法最好,但同时觉得也很高级,英文)http://charlesleifer.com/blog/querying-tree-structures-in-sqlite-using-python-and-the-transitive-closure-extension/
以上这篇SQL 双亲节点查找所有子节点的实现方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持查字典教程网。
【SQL 双亲节点查找所有子节点的实现方法】相关文章: