公司编辑妹子需要爬取网页内容,叫我帮忙做了一简单的爬取工具
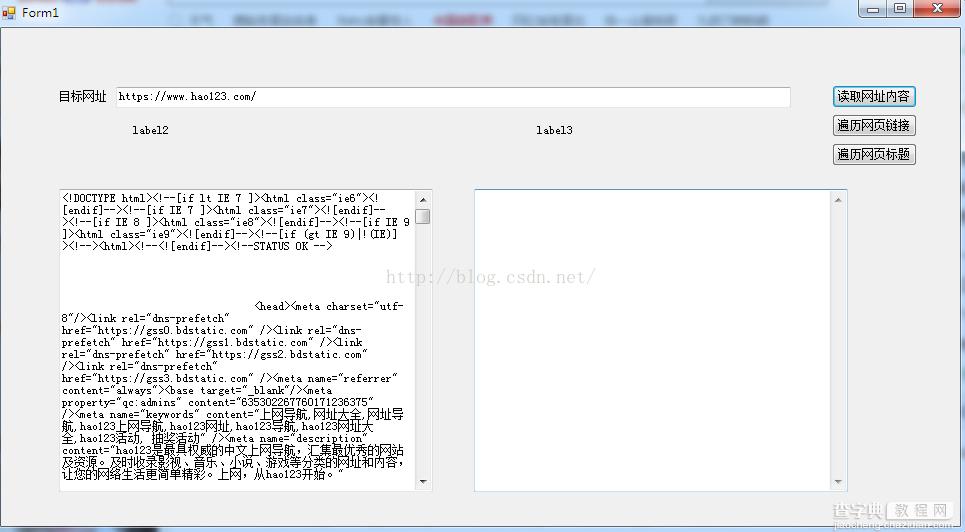
这是爬取网页内容,像是这对大家来说都是不难得,但是在这里有一些小改动,代码献上,大家参考
private string GetHttpWebRequest(string url) { HttpWebResponse result; string strHTML = string.Empty; try { Uri uri = new Uri(url); WebRequest webReq = WebRequest.Create(uri); WebResponse webRes = webReq.GetResponse(); HttpWebRequest myReq = (HttpWebRequest)webReq; myReq.UserAgent = "User-Agent:Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; .NET CLR 1.0.3705"; myReq.Accept = "*/*"; myReq.KeepAlive = true; myReq.Headers.Add("Accept-Language", "zh-cn,en-us;q=0.5"); result = (HttpWebResponse)myReq.GetResponse(); Stream receviceStream = result.GetResponseStream(); StreamReader readerOfStream = new StreamReader(receviceStream, System.Text.Encoding.GetEncoding("utf-8")); strHTML = readerOfStream.ReadToEnd(); readerOfStream.Close(); receviceStream.Close(); result.Close(); } catch { Uri uri = new Uri(url); WebRequest webReq = WebRequest.Create(uri); HttpWebRequest myReq = (HttpWebRequest)webReq; myReq.UserAgent = "User-Agent:Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; .NET CLR 1.0.3705"; myReq.Accept = "*/*"; myReq.KeepAlive = true; myReq.Headers.Add("Accept-Language", "zh-cn,en-us;q=0.5"); //result = (HttpWebResponse)myReq.GetResponse(); try { result = (HttpWebResponse)myReq.GetResponse(); } catch (WebException ex) { result = (HttpWebResponse)ex.Response; } Stream receviceStream = result.GetResponseStream(); StreamReader readerOfStream = new StreamReader(receviceStream, System.Text.Encoding.GetEncoding("gb2312")); strHTML = readerOfStream.ReadToEnd(); readerOfStream.Close(); receviceStream.Close(); result.Close(); } return strHTML; }
这是根据url爬取网页远吗,有一些小改动,很多网页有不同的编码格式,甚至有些网站做了反爬取的防范,这个方法经过能够改动也能爬去
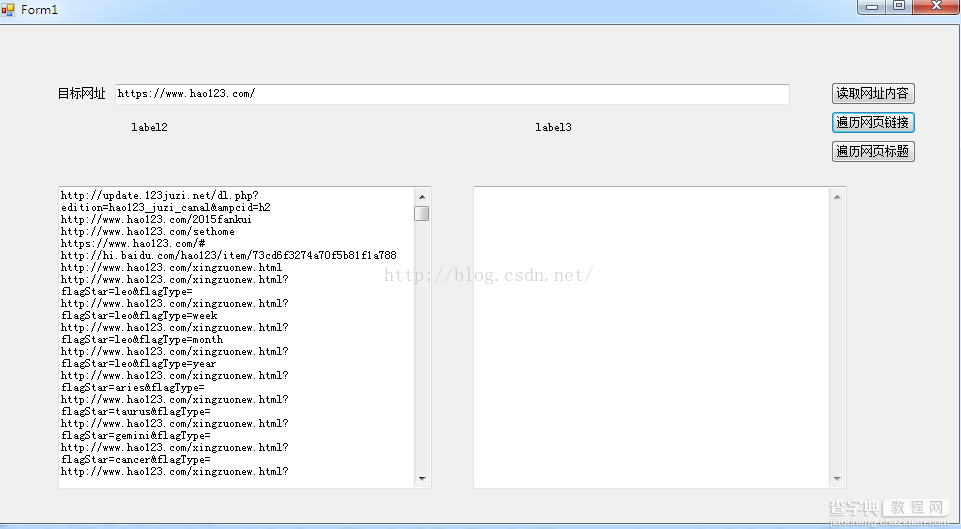
以下是爬取网页所有的网址链接
/// <summary> /// 提取HTML代码中的网址 /// </summary> /// <param name="htmlCode"></param> /// <returns></returns> private static List<string> GetHyperLinks(string htmlCode, string url) { ArrayList al = new ArrayList(); bool IsGenxin = false; StringBuilder weburlSB = new StringBuilder();//SQL StringBuilder linkSb = new StringBuilder();//展示数据 List<string> Weburllistzx = new List<string>();//新增 List<string> Weburllist = new List<string>();//旧的 string ProductionContent = htmlCode; Regex reg = new Regex(@"http(s)?://([w-]+.)+[w-]+/"); string wangzhanyuming = reg.Match(url, 0).Value; MatchCollection mc = Regex.Matches(ProductionContent.Replace("href="/", "href="" + wangzhanyuming).Replace("href='/", "href='" + wangzhanyuming).Replace("href=/", "href=" + wangzhanyuming).Replace("href="./", "href="" + wangzhanyuming), @"<[aA][^>]* href=[^>]*>", RegexOptions.Singleline); int Index = 1; foreach (Match m in mc) { MatchCollection mc1 = Regex.Matches(m.Value, @"[a-zA-z]+://[^s]*", RegexOptions.Singleline); if (mc1.Count > 0) { foreach (Match m1 in mc1) { string linkurlstr = string.Empty; linkurlstr = m1.Value.Replace(""", "").Replace("'", "").Replace(">", "").Replace(";", ""); weburlSB.Append("$-$"); weburlSB.Append(linkurlstr); weburlSB.Append("$_$"); if (!Weburllist.Contains(linkurlstr) && !Weburllistzx.Contains(linkurlstr)) { IsGenxin = true; Weburllistzx.Add(linkurlstr); linkSb.AppendFormat("{0}<br/>", linkurlstr); } } } else { if (m.Value.IndexOf("javascript") == -1) { string amstr = string.Empty; string wangzhanxiangduilujin = string.Empty; wangzhanxiangduilujin = url.Substring(0, url.LastIndexOf("/") + 1); amstr = m.Value.Replace("href="", "href="" + wangzhanxiangduilujin).Replace("href='", "href='" + wangzhanxiangduilujin); MatchCollection mc11 = Regex.Matches(amstr, @"[a-zA-z]+://[^s]*", RegexOptions.Singleline); foreach (Match m1 in mc11) { string linkurlstr = string.Empty; linkurlstr = m1.Value.Replace(""", "").Replace("'", "").Replace(">", "").Replace(";", ""); weburlSB.Append("$-$"); weburlSB.Append(linkurlstr); weburlSB.Append("$_$"); if (!Weburllist.Contains(linkurlstr) && !Weburllistzx.Contains(linkurlstr)) { IsGenxin = true; Weburllistzx.Add(linkurlstr); linkSb.AppendFormat("{0}<br/>", linkurlstr); } } } } Index++; } return Weburllistzx; }
这块的技术其实就是简单的使用了正则去匹配!接下来献上获取标题,以及存储到xml文件的方法
/// <summary> /// // 把网址写入xml文件 /// </summary> /// <param name="strURL"></param> /// <param name="alHyperLinks"></param> private static void WriteToXml(string strURL, List<string> alHyperLinks) { XmlTextWriter writer = new XmlTextWriter(@"D:HyperLinks.xml", Encoding.UTF8); writer.Formatting = Formatting.Indented; writer.WriteStartDocument(false); writer.WriteDocType("HyperLinks", null, "urls.dtd", null); writer.WriteComment("提取自" + strURL + "的超链接"); writer.WriteStartElement("HyperLinks"); writer.WriteStartElement("HyperLinks", null); writer.WriteAttributeString("DateTime", DateTime.Now.ToString()); foreach (string str in alHyperLinks) { string title = GetDomain(str); string body = str; writer.WriteElementString(title, null, body); } writer.WriteEndElement(); writer.WriteEndElement(); writer.Flush(); writer.Close(); } /// <summary> /// 获取网址的域名后缀 /// </summary> /// <param name="strURL"></param> /// <returns></returns> private static string GetDomain(string strURL) { string retVal; string strRegex = @"(.com/|.net/|.cn/|.org/|.gov/)"; Regex r = new Regex(strRegex, RegexOptions.IgnoreCase); Match m = r.Match(strURL); retVal = m.ToString(); strRegex = @".|/$"; retVal = Regex.Replace(retVal, strRegex, "").ToString(); if (retVal == "") retVal = "other"; return retVal; } /// <summary> /// 获取标题 /// </summary> /// <param name="html"></param> /// <returns></returns> private static string GetTitle(string html) { string titleFilter = @"<title>[sS]*"; string h1Filter = @"<h1.*?>.*"; string clearFilter = @"<.*"; string title = ""; Match match = Regex.Match(html, titleFilter, RegexOptions.IgnoreCase); if (match.Success) { title = Regex.Replace(match.Groups[0].Value, clearFilter, ""); } // 正文的标题一般在h1中,比title中的标题更干净 match = Regex.Match(html, h1Filter, RegexOptions.IgnoreCase); if (match.Success) { string h1 = Regex.Replace(match.Groups[0].Value, clearFilter, ""); if (!String.IsNullOrEmpty(h1) && title.StartsWith(h1)) { title = h1; } } return title; }
这就是所用的全部方法,还是有很多需要改进之处!大家如果有发现不足之处还请指出,谢谢!
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持查字典教程网。
【C#网络爬虫代码分享 C#简单的爬取工具】相关文章: