内存映射文件原理
首先说说这篇文章要解决什么问题?
1.虚拟内存与内存映射文件的区别与联系.
2.内存映射文件的原理.
3.内存映射文件的效率.
4.传统IO和内存映射效率对比.
虚拟内存与内存映射文件的区别与联系
二者的联系
虚拟内存和内存映射文件都是将一部分内容加载到,另一部分放在磁盘上的一种机制,二者都是应用程序动态性的基础,由于二者的虚拟性,对于用户都是透明的.
虚拟内存其实就是硬盘的一部分,是计算机RAM与硬盘的数据交换区,因为实际的物理内存可能远小于进程的地址空间,这就需要把内存中暂时不用到的数据放到硬盘上一个特殊的地方,当请求的数据不在内存中时,系统产生却页中断,内存管理器便将对应的内存页重新从硬盘调入物理内存。
内存映射文件是由一个文件到一块内存的映射,使应用程序可以通过内存指针对磁盘上的文件进行访问,其过程就如同对加载了文件的内存的访问,因此内存文件映射非常适合于用来管理大文件。
二者的区别
1.虚拟内存使用硬盘只能是页面文件,而内存映射使用的磁盘部分可以是任何磁盘文件.
2.二者的架构不同,或者是说应用的场景不同,虚拟内存是架构在物理内存之上,其引入是因为实际的物理内存运行程序所需的空间,即使现在计算机中的物理内存越来越大,程序的尺寸也在增长。将所有运行着的程序全部加载到内存中不经济也非常不现实。内存映射文件架构在程序的地址空间之上,32位机地址空间只有4G,而某些大文件的尺寸可要要远超出这个值,因此,用地址空间中的某段应用文件中的一部分可解决处理大文件的问题,在32中,使用内存映射文件可以处理2的64次(64EB)大小的文件.原因内存映射文件,除了处理大文件,还可用作进程间通信。
内存映射文件的原理
“映射”就是建立一种对应关系,在这里主要是指硬盘上文件的位置与进程逻辑地址空间中一块相同区域之间一一对应,这种关系纯属是逻辑上的概念,物理上是不存在的,原因是进程的逻辑地址空间本身就是不存在的,在内存映射过程中,并没有实际的数据拷贝,文件没有被载入内存,只是逻辑上放入了内存,具体到代码,就是建立并初始化了相关的数据结构,这个过程有系统调用mmap()实现,所以映射的效率很高.
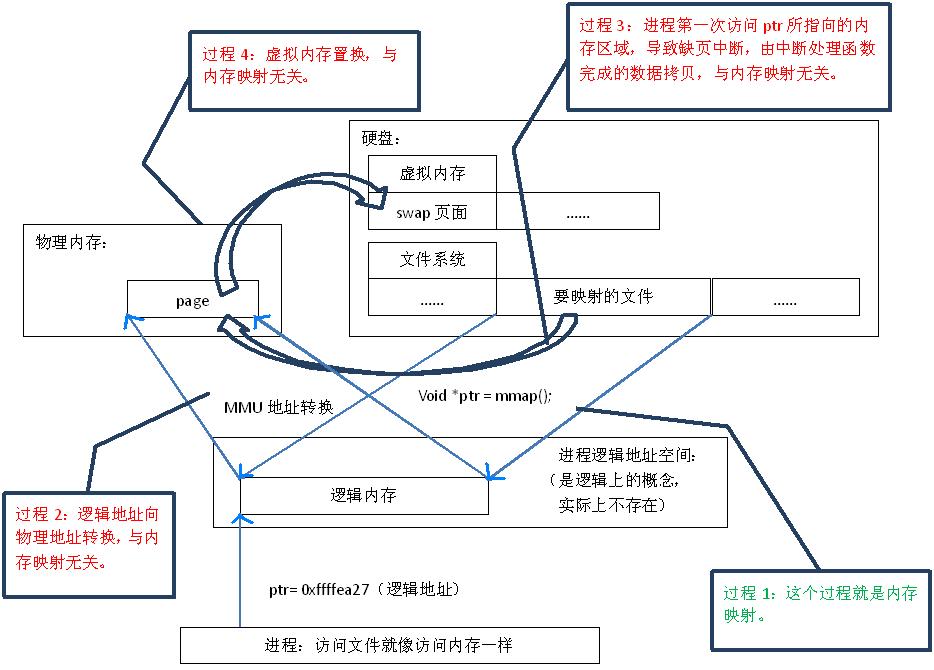
内存映射原理
上面说到建立内存映射没有进行实际的数据拷贝,那么进行进程又怎么能最终通过内存操作访问到硬盘上的文件呢?
看上图:
1.调用mmap(),相当于要给进行内存映射的文件分配了虚拟内存,它会返回一个指针ptr,这个ptr所指向的是一个逻辑地址,要操作其中的数据,必须通过MMU将逻辑地址转换成物理地址,如图1中过程2所示。
2.建立内存映射并没有实际拷贝数据,这时,MMU在地址映射表中是无法找到与ptr相对应的物理地址的,也就是MMU失败,将产生一个缺页中断,缺 页中断的中断响应函数会在swap中寻找相对应的页面,如果找不到(也就是该文件从来没有被读入内存的情况),则会通过mmap()建立的映射关系,从硬 盘上将文件读取到物理内存中,如图1中过程3所示。
3.如果在拷贝数据时,发现物理内存不够用,则会通过虚拟内存机制(swap)将暂时不用的物理页面交换到硬盘上,如图1中过程4所示。
内存映射文件的效率
了解过内存映射文件都知道,它比传统的IO读写数据快很多,那么,它为什么会这么快,从代码层面上来看,从硬盘上将文件读入内存,都是要经过数据拷贝,并且数据拷贝操作是由文件系统和硬件驱动实现的,理论上来说,拷贝数据的效率是一 样的。其实,原因是read()是系统调用,其中进行了数据 拷贝,它首先将文件内容从硬盘拷贝到内核空间的一个缓冲区,如图2中过程1,然后再将这些数据拷贝到用户空间,如图2中过程2,在这个过程中,实际上完成 了两次数据拷贝 ;而mmap()也是系统调用,如前所述,mmap()中没有进行数据拷贝,真正的数据拷贝是在缺页中断处理时进行的,由于mmap()将文件直接映射到用户空间,所以中断处理函数根据这个映射关系,直接将文件从硬盘拷贝到用户空间,只进行了 一次数据拷贝 。因此,内存映射的效率要比read/write效率高。
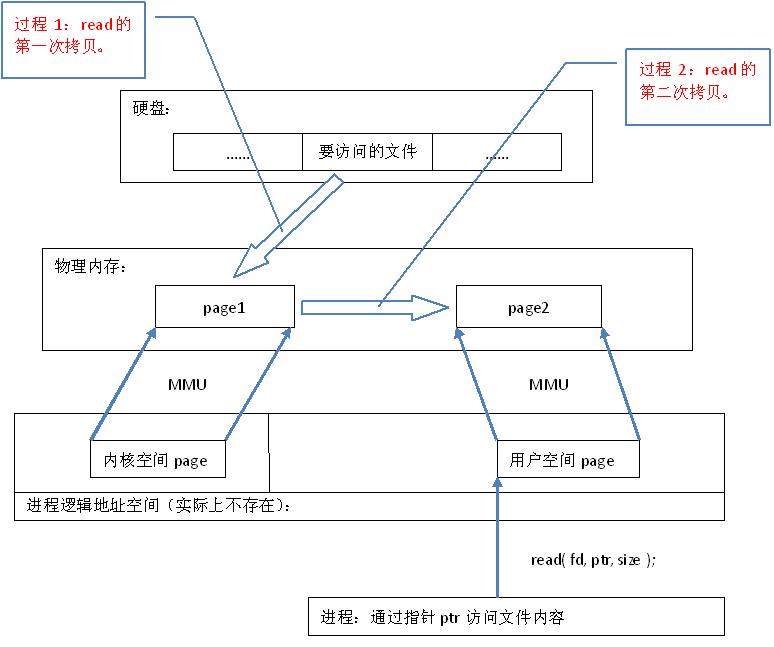
read系统调用原理
传统IO和内存映射效率对比.
在这里,使用java传统的IO,加缓冲区的IO,内存映射分别读取10M数据.用时如下:
public class MapBufDelete { public static void main(String[] args) { try { FileInputStream fis=new FileInputStream("./largeFile.txt"); int sum=0; int n; long t1=System.currentTimeMillis(); try { while((n=fis.read())>=0){ // 数据处理 } } catch (IOException e) { e.printStackTrace(); } long t=System.currentTimeMillis()-t1; System.out.println("传统IOread文件,不使用缓冲区,用时:"+t); } catch (FileNotFoundException e) { e.printStackTrace(); } try { FileInputStream fis=new FileInputStream("./largeFile.txt"); BufferedInputStream bis=new BufferedInputStream(fis); int sum=0; int n; long t1=System.currentTimeMillis(); try { while((n=bis.read())>=0){ // 数据处理 } } catch (IOException e) { e.printStackTrace(); } long t=System.currentTimeMillis()-t1; System.out.println("传统IOread文件,使用缓冲区,用时:"+t); } catch (FileNotFoundException e) { e.printStackTrace(); } MappedByteBuffer buffer=null; try { buffer=new RandomAccessFile("./largeFile.txt","rw").getChannel().map(FileChannel.MapMode.READ_WRITE, 0, 1253244); int sum=0; int n; long t1=System.currentTimeMillis(); for(int i=0;i<1024*1024*10;i++){ // 数据处理 } long t=System.currentTimeMillis()-t1; System.out.println("内存映射文件读取文件,用时:"+t); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); }finally { } } }
运行结果
传统IOread文件,不使用缓冲区,用时:4739
传统IOread文件,使用缓冲区,用时:59
内存映射文件读取文件,用时:11
最后,解释一下,为什么使用缓冲区读取文件会比不使用快:
原因是每次进行IO操作,都要从用户态陷入内核态,由内核把数据从磁盘中读到内核缓冲区,再由内核缓冲区到用户缓冲区,如果没有buffer,读取都需要从用户态到内核态切换,而这种切换很耗时,所以,采用预读,减少IO次数,如果有buffer,根据局部性原理,就会一次多读数据,放到缓冲区中,减少了IO次数.
感谢阅读,希望能帮助到大家,谢谢大家对本站的支持!
【java 深入理解内存映射文件原理】相关文章:
★ android中图片的三级缓存cache策略(内存/文件/网络)
★ Android使用Pull解析器解析xml文件的实现代码