和 MongoDB 类似 RethinkDB 是一个主要用来存储 JSON 文档的数据库引擎(MongoDB 存储的是 BSON),可以轻松和多个节点连成分布式数据库,非常好用的查询语言以及支持表的 joins 和 group by 操作等。
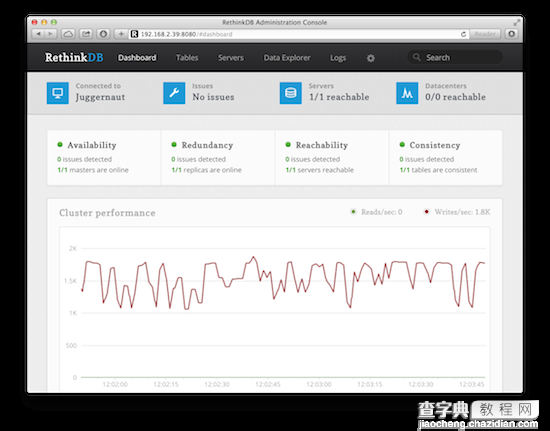
昨天试玩了一下 RethinkDB,在一台虚拟机上测试,插入2500万行记录性能比较稳定,维持在 1.5K 行到 2K 行每秒之间,RethinkDB 的数据分片(sharding)功能非常简单,一个点击就可以完成。下面的安装和测试在 Ubuntu 12.04.4 LTS Server 版本上完成。
加入 RethinkDB 官方源后安装:
复制代码 代码如下:$ sudo apt-get install python-software-properties
$ sudo add-apt-repository ppa:rethinkdb/ppa
$ sudo apt-get update
$ sudo apt-get install rethinkdb
拷贝一个例子配置文件后修改 bind 部分以便可以从其他机器访问:
复制代码 代码如下:$ cd /etc/rethinkdb/
$ sudo cp default.conf.sample instances.d/default.conf
$ sudo vi instances.d/default.conf
...
# bind=127.0.0.1
bind=0.0.0.0
...
启动 rethinkdb:
复制代码 代码如下:$ sudo /etc/init.d/rethinkdb start
rethinkdb: default: Starting instance. (logging to `/var/lib/rethinkdb/default/data/log_file')
访问 http://192.168.2.39:8080/ 就可以看到 rethinkdb 的管理界面了:
|
如果不喜欢在命令行工作,web 界面还提供了 Data Explorer 在线查询工具,支持语法高亮、在线函数提示等,不用额外查帮助文件。
|
要用程序的方式和 rethinkdb 打交道的话就需要安装客户端驱动(client drivers),官方支持的驱动有 JavaScript, Ruby 和 Python 3种语言,社区支持的驱动几乎包括了 C, Go, C++, Java, PHP, Perl, Clojure, Erlang 等所有主流编程语言。本人用 Python 多一些,所以这里安装 Python 客户端驱动:
复制代码 代码如下:$ sudo apt-get install python-pip
$ sudo pip install rethinkdb
测试一下驱动是否能工作了,如果 import rethinkdb 没有出错基本就可以说明模块安装成功:
复制代码 代码如下:$ python
Python 2.7.3 (default, Feb 27 2014, 19:58:35)
[GCC 4.6.3] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import rethinkdb
>>>
gene2go.txt 是一个含有基因数据的文本文件,大概1000多万行记录,格式如下:
复制代码 代码如下:$ head -2 gene2go.txt
#Format: tax_id GeneID GO_ID Evidence Qualifier GO_term PubMed Category (tab is used as a separator, pound sign - start of a comment)
3702814629GO:0005634ISM-nucleus-Component
写个简单程序把 gene2go.txt 的数据导入到 rethinkdb 里:
复制代码 代码如下:#!/usr/bin/python
# -*- coding: UTF-8 -*-
import os, os.path, sys, re, csv, string
def csv2db():
data = csv.reader(open('gene2go.txt', 'rb'), delimiter='t')
data.next()
import rethinkdb as r
r.connect('localhost', 28015).repl()
r.db('test').table_create('gene2go').run()
gene2go = r.db('test').table('gene2go')
for row in data:
gene2go.insert({
'tax_id': row[0],
'GeneID': row[1],
'GO_ID': row[2],
'Evidence': row[3],
'Qualifier': row[4],
'GO_term': row[5],
'PubMed': row[6],
'Category': row[7]
}).run(durability="soft", noreply=True)
def main():
csv2db()
if __name__ == "__main__":
main()
【Python使用RethinkDB总结】相关文章:
★ SQL like子句的另一种实现方法(速度比like快)
★ 取随机记录的语句